



Béziers, Bivariates, and Beyond
Some Tricks I Wish I Knew Earlier

This week, I spent time thinking about a few tricks that I've picked since the time I stopped regularly blogging that I have found particularly useful for soccer analytics, and where I've found them. A few of them have sample code available in my Soccer Analytics Handbook, which probably needs an update at this point!
Single-Pixel Selection – Javier Fernandez and Luke Bornn, SoccerMap: A Deep Learning Architecture for Visually-Interpretable Analysis in Soccer
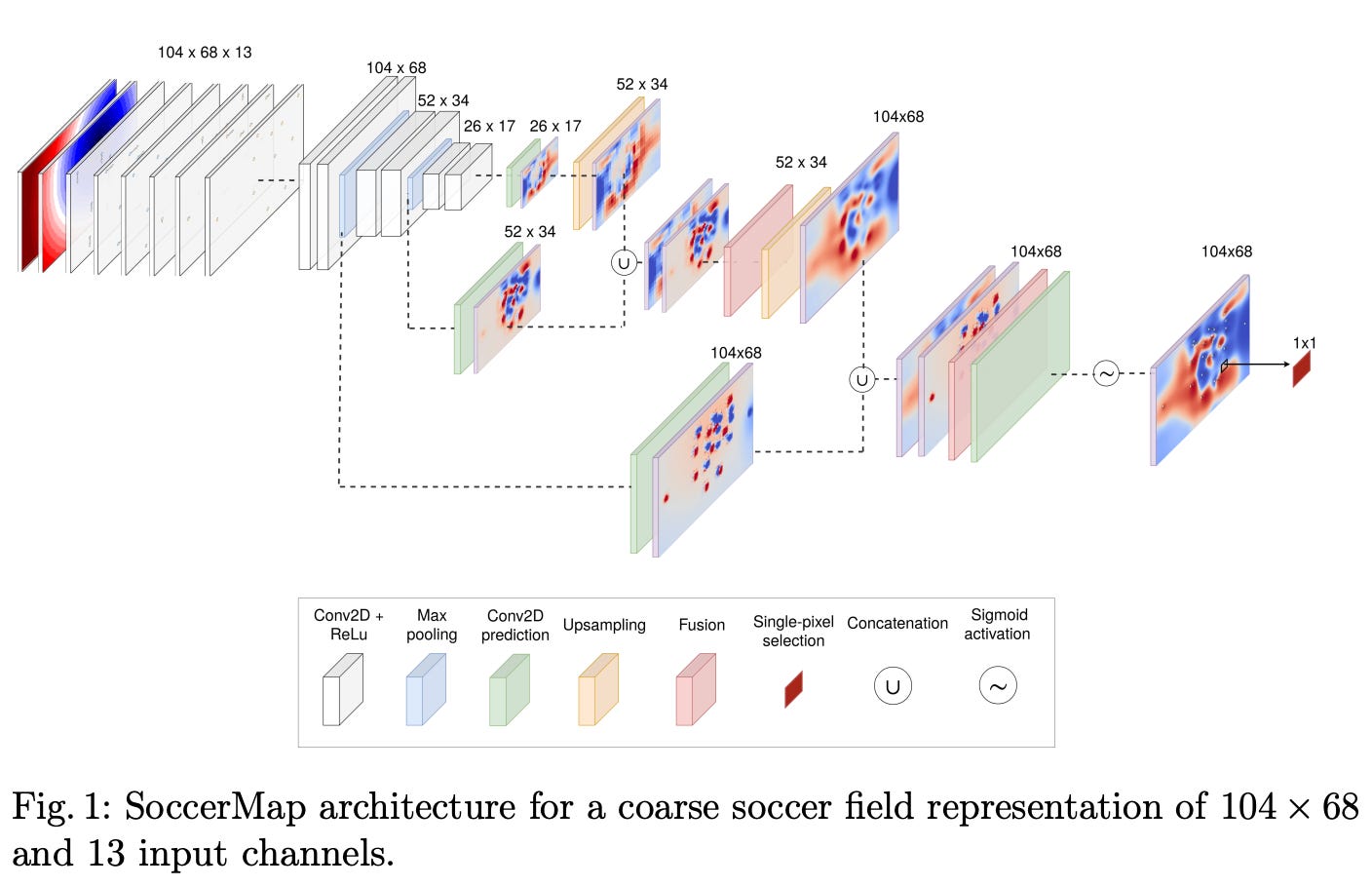
This elegant technique blew my mind when I first dug a bit deeper into this paper, and opened my eyes to the surprising flexibility of deep learning. When building a pass difficulty model in a supervised manner – as opposed to Spearman's physical approach (which I adore!) – it certainly was not obvious to me how you would produce a continuous probability surface from a training set of passes.
Since only a single point in the true output surface is observed – the event’s location – the prediction problem becomes significantly more complex. SoccerMap “provides a novel solution for learning a full prediction surface when there is only a single-pixel correspondence between ground-truth outcomes and the predicted probability map.” Even evaluating loss at just one pixel, the model can infer continuous probabilities across the entire field. Really clever, and super useful.
Monotonic Constraints – Dinesh Vatvani, Upgrading Expected Goals
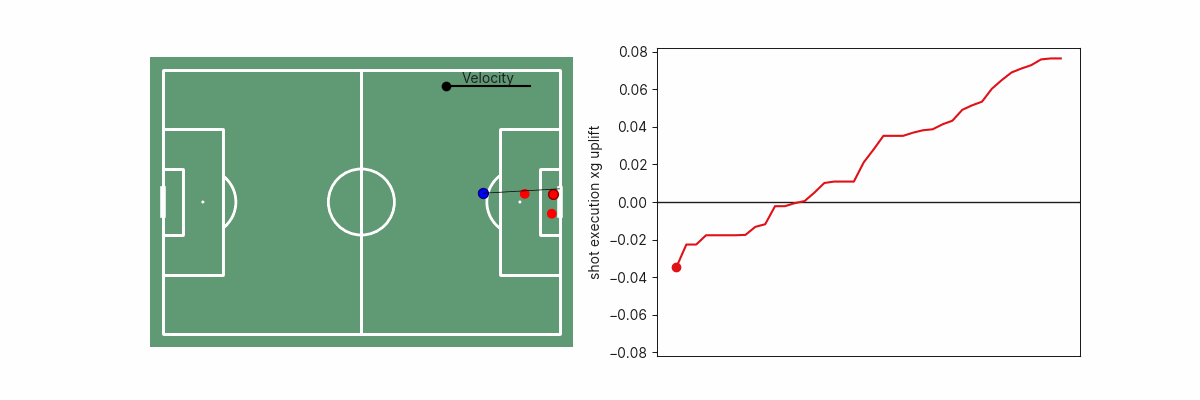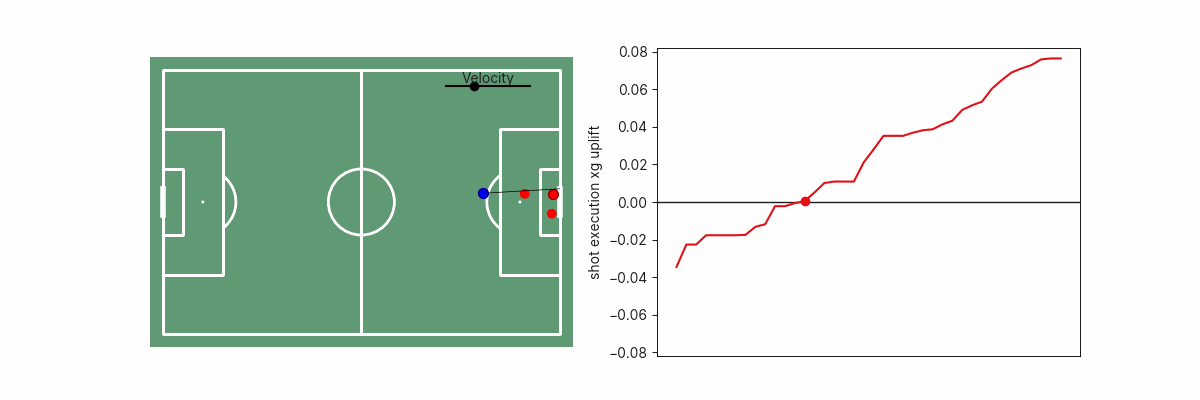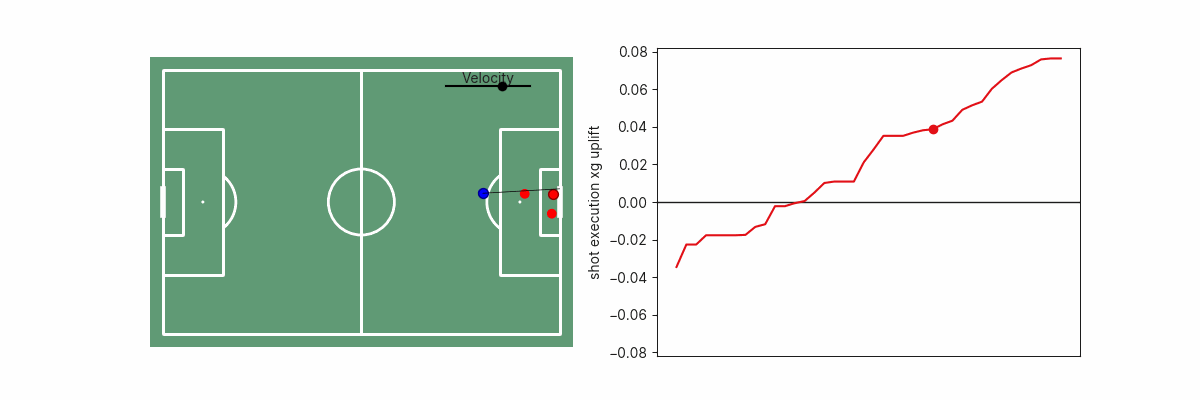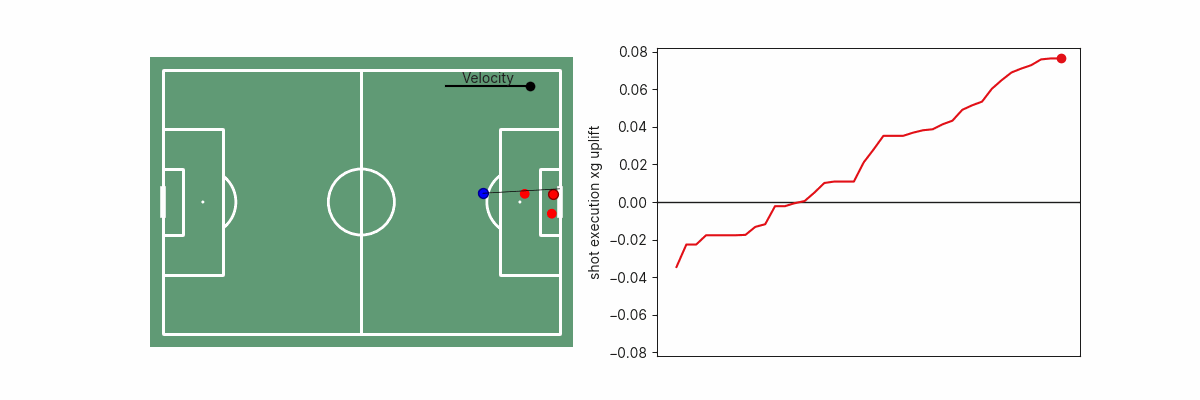
Sometimes you should be opinionated about your data, but it hasn't always been clear to me how to make my opinions known to a model. In this Statsbomb white paper, Dinesh demonstrated an easy-to-grasp concept for controlling your gradient boosted decision tree models by applying monotonic constraints on certain features.
In other words, this allows you to force certain attributes to always have a positive or a negative effect on the model. For example, in a post-shot xG model, it might be reasonable to force goal probability to always increase alongside ball velocity. When you're confident about your assumptions, this is a great method to help prevent model overfitting.
Clustering Bézier Curves – Sam Gregory, Ready Player Run: Off-ball run identification and classification
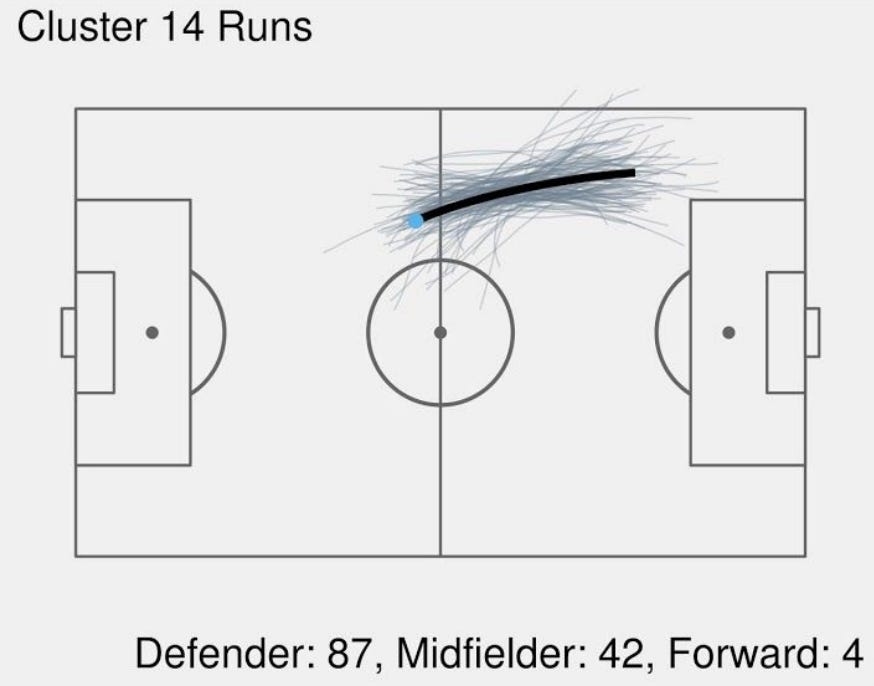
The first time this concept (outside of Adobe Illustrator) came on my radar was actually via the Miller and Bornn 2017 paper, but Sam did a great job bringing the techniques into soccer for the purposes of clustering run types.
Bézier curves serve as a unintuitive yet remarkably robust method for dimensionality reduction on player tracks. They can reduce complicated trajectories of varying frame lengths down to vectors of a consistent shape and size, allowing for all kinds of potential downstream analysis like clustering.
Player Position Distributions – Laurie Shaw and Mark Glickman, Dynamic analysis of team strategy in professional football
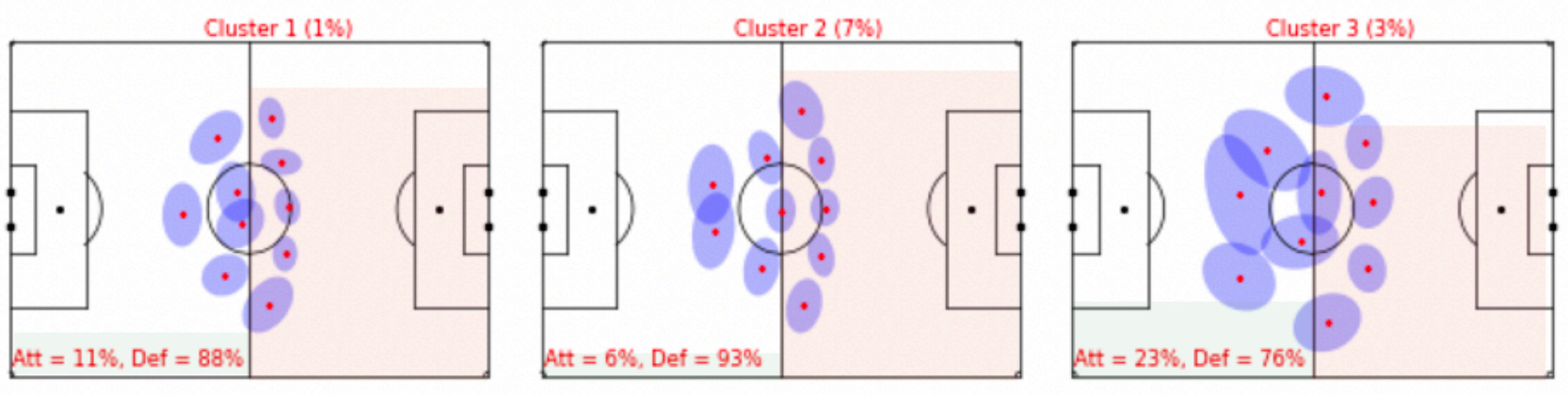
This is one of my favourite soccer analytics papers of all time. Not necessarily because it's the best way for identifying shifts in team formation – I think there are better ways to do that these days – but because of all the different tricks that Laurie uses in the paper.
The most impactful one (for me, at least) is the modelling of each player's position as a bivariate normal distribution with a covariance matrix estimating the extent of a player's positional deviation. It’s a clear upgrade over plotting average positions where you don’t have any understanding of positional variability.
Player Order Invariance – The Zoo, Big Data Bowl 2020 Winner
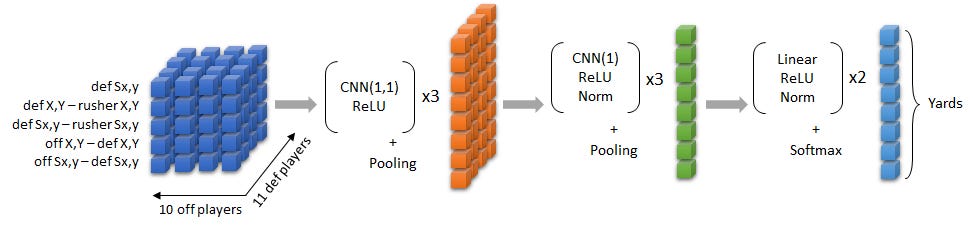
Honestly, I'm not completely sure that I understand how this one works. When playing around with neural networks, I have struggled to find architectures that produce deterministic outcomes no matter what order I populate the players features into a vector. In the past I mostly side-stepped this issue and went the route of sparse matrices or team-level surfaces that played nicely with the convolutional layers that seemed to be doing the heavy lifting.
This winning entry of the 2020 Big Data bowl utilizes a 1x1 CNN layer with pooling to process a dense tensor of relative player features. This technique allows for player order invariance and allows the state to be represented in a much more economical fashion. GNN's are probably the modern solution to this now, but this opened my eyes to a whole new world of possibility.
Pareto Frontier – Ian Graham, How to Win the Premier League
Unlike most concepts in soccer analytics, Ian didn’t invent this one. However, he did introduce it to the soccer analytics canon in the chapter Stats and Snakeoil, under the section The Tyranny of Metrics. His explanation gave me a fresh perspective on player profiles and highlighted the risks of relying on too many metrics for player evaluation.
The Pareto Frontier represents the line where individual players achieve the best possible trade-off between two or more competing metrics. Players on this frontier are those for whom improving one metric would necessarily worsen another, forming the outer boundary of performance for the given metrics. In the book, Ian uses Expected Assists and Pressure Regains as an example. If you’re looking for a player with both, there will be many players who have a lot of one given the other.
The key takeaway is that as you extend this concept to include a large number of metrics, the likelihood increases that any player might sit on the Pareto Frontier for some combination of metrics. This enables you to find a context where any player can be framed as “the best” at something, based on certain trade-offs. While this flexibility might seem appealing, it can easily lead to misleading conclusions, underscoring the need for caution.
Tools for Tiny Teams – Ben Torvaney, Stats and Snakeoil
To round out this list, and to keep our feet on the ground, I wanted to add my favourite blog post of the last few years. A lot of analytics teams are tiny and don't have the time or resources to chase some of the exciting ideas above. The principals discussed in this post will get you most of the way there.
I find myself going back to this blog post every couple of months and pick up something new. On my latest read, I learned about unaccent for Postgres – neat! While I've moved away from it recently, we also implemented dbt because I learned about it here. It's all good advice.